
Hackernews article
Google Gemini Prompt Injection Flaw Exposed Private Calendar Data via Malicious Invites
The money quote: “The vulnerability, Miggo Security’s Head of Research, Liad Eliyahu, said, made it possible to circumvent Google Calendar’s privacy controls by hiding a dormant malicious payload within a standard calendar invite.”
How is it done?
The starting point of the attack chain is a new calendar event that’s crafted by the threat actor and sent to a target. The invite’s description embeds a natural language prompt that’s designed to do their bidding, resulting in a prompt injection.
The attack gets activated when a user asks Gemini a completely innocuous question about their schedule (e.g., Do I have any meetings for Tuesday?), prompting the artificial intelligence (AI) chatbot to parse the specially crafted prompt in the aforementioned event’s description to summarize all of users’ meetings for a specific day, add this data to a newly created Google Calendar event, and then return a harmless response to the user.
“Behind the scenes, however, Gemini created a new calendar event and wrote a full summary of our target user’s private meetings in the event’s description,” Miggo said. “In many enterprise calendar configurations, the new event was visible to the attacker, allowing them to read the exfiltrated private data without the target user ever taking any action.”
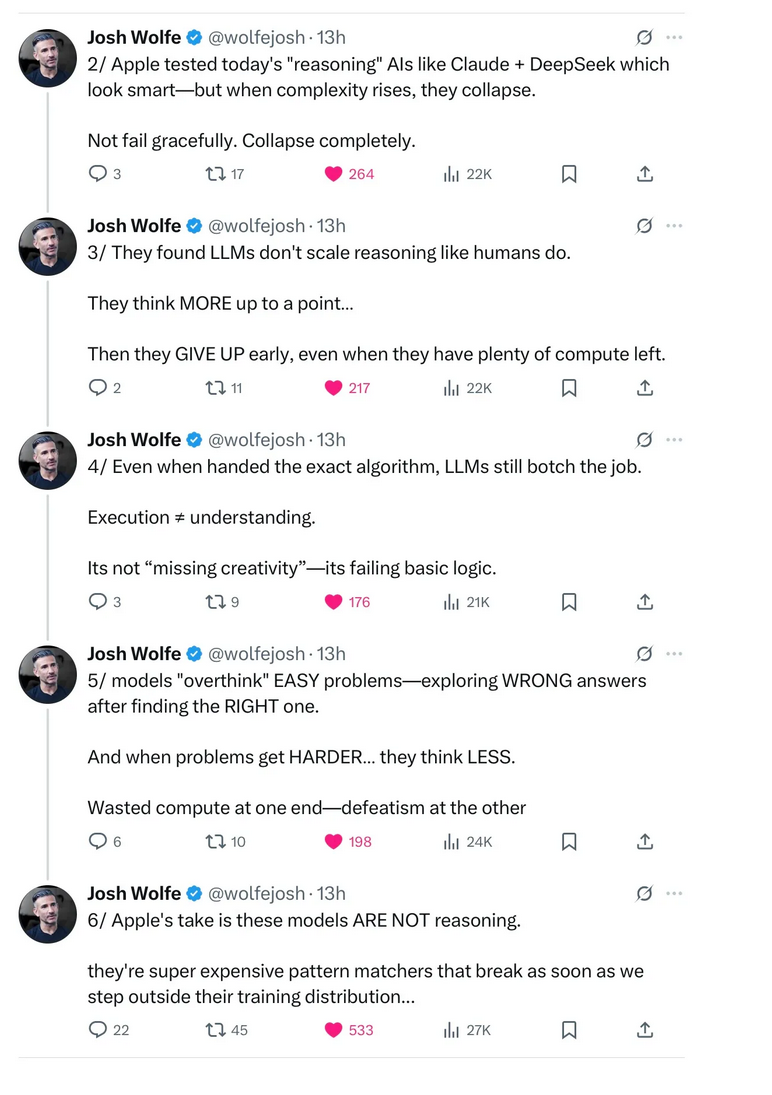
Thus this is just another instance of problems within the current iteration model of the LLM (Large Language Model). This makes me wonder what other problems are there for LLM AI?
I just watched a Steve Eisman youtube video with Gary Marcus a well known AI researcher which has cataloged the AI problems in research papers.
So I wanted to uncover all the areas of concern by Gary Marcus for LLM, so I asked you.com this:
“What are the architectural and fundamental problems with LLM AI ? Hallucinations and not having a world model is one and what are other problems as Gary Marcus and his research has noted? I am interested from a cybersecurity professional in the industry for 20 years”
Remember that asking a good question with Role, Objective, Context, instruction. It took a few minutes for the answer to arrive:
1. Gary Marcus’s Core Critiques of LLM Architecture
| Problem Area | Explanation | Example/Detail |
|---|---|---|
| Lack of Genuine Reasoning | LLMs rely on statistical pattern matching, not true logic or understanding
. |
Fail at algorithmic tasks (e.g., Tower of Hanoi) |
| Brittleness & Poor Generalization | Perform well on familiar data but break down with novel or rephrased tasks
. |
Fragile to small task variations |
| No Compositional/Symbolic Reasoning | Cannot systematically combine concepts or follow rules
. |
Struggle with analogies, math, and logic |
| No Robust World Models | Lack explicit, predictive models of the world
. |
Use heuristics, not true simulation or reasoning |
| Poor Abstraction/Common Sense | Make “boneheaded mistakes” due to lack of common sense
. |
Fail at basic real-world reasoning |
| Impenetrability/Opacity | Black-box nature makes outputs hard to interpret or trust
. |
Opaque decision-making |
| Scaling Limitations | More data/compute yields diminishing returns; doesn’t solve core issues
. |
Scaling doesn’t fix reasoning/abstraction deficits |
| No Hybrid Symbolic Integration | Purely subsymbolic, lacking explicit rule-based reasoning
. |
Advocates for neuro-symbolic hybrid systems |
So there is obviously a lot here to unpack – minimally we have chronicled some hallucinations (which is the fancy word for errors in LLM). But obviously the LLM AI has some structural issues.
I can probably summarize the above in the following:
LLM AI does not do original thinking and thus it also has multiple problems especially because the nature of the beast is that statistically predicting words to answer questions is statistically bad. It works in some situations, but the true 6 sigma level of accuracy is impossible. remember 6 sigma is .999999 accurate. i.e. 99% accurate means 1% error.
.999999 accurate means .000001 error. 1 in a million. In some situations like driving for a million miles you do not want to have lower than 1 mile in a million miles being error prone. In life and death situations what is an acceptable error rate? Definitely not 99% accurate. I do not want to dissect the rest of Gary Marcus information assuming you.com accurately summarized his research.
If you notice I did not ask the AI to create something new, only to read and catalog or summarize. I would say that the left column is accurate, the middle is also likely accurate, but the right column may not be 100% accurate. I will have to do more research.
More interesting to me is the rest:
Broader Technical and Architectural Limitations
| Limitation | Description | Fundamental or Solvable? |
|---|---|---|
| Reasoning Failures | Inability to perform robust, multi-step, human-like reasoning
. |
Largely fundamental |
| Compositionality | Poor at systematic generalization and modularity
. |
Fundamental, partial progress |
| Causal Inference | Shallow causal reasoning; confuse correlation with causation
. |
Fundamental, hybrid solutions |
| Training Data Dependence | Overfitting, memorization, poor OOD generalization
. |
Partially solvable |
| Context Window Constraints | Limited long-term memory and context handling
. |
Architectural, ongoing |
| Alignment Problems | Misalignment with user intent, value, and safety
. |
Partially solvable |
| Emergent Unpredictability | Sudden, unpredictable abilities and risks at scale
. |
Fundamental |
| Resource/Efficiency | High computational and energy costs
. |
Engineering, partially solvable
|
and finally:
3. Cybersecurity Implications: How LLM Flaws Become Attack Surfaces
| Vulnerability Type | Example Attack Vector/Scenario | Security Impact |
|---|---|---|
| Prompt Injection | Indirect injection via web content or user input | Data exfiltration, privilege escalation |
| Data/Model Poisoning | Backdoor trigger in fine-tuned model | Persistent compromise, biased outputs |
| Adversarial Example | Crafted input causes code execution in downstream system | Remote code execution, XSS, SQLi |
| Model Extraction | Repetitive queries reconstruct model weights | IP theft, privacy breach |
| Privacy Leakage | Prompt elicits memorized PII | Compliance violation, data breach |
| Hallucination | LLM generates false financial advice | Financial loss, reputational damage |
| Supply Chain Attack | Compromised plugin introduces malware | System compromise, lateral movement |
| Excessive Agency | Over-privileged agent deletes critical data | Data loss, operational disruption |
| Resource Exhaustion | Large input causes DoS | Service outage, cost spike |
Key Finding:
The architectural weaknesses of LLMs—especially their susceptibility to manipulation, lack of verification, and opacity—directly translate into exploitable vulnerabilities in enterprise settings. Prompt injection, data poisoning, and privacy leakage are among the most critical risks
The above section looks to have good amount of source links. and my comment…
To revisit the Hackernews article on the problem the above list is general in nature and must be kept in mind. The specific of Google gemini and enterprise calendars being modified need a guard rail. The bottom line needs to said that it is too early to give much actual control to AI agents or software control. And yes the hacker has a dream tool to make things difficult for us on defense.
you.com conclusion is:
Conclusion & Recommendations
Summary:
LLMs, as currently architected, are fundamentally limited in reasoning, generalization, and transparency. Gary Marcus’s research underscores that these are not just technical bugs, but deep design flaws. For cybersecurity professionals, these flaws create a broad and evolving attack surface—prompt injection, data/model poisoning, adversarial manipulation, and privacy leakage are real and present dangers.
Recommendations for Cybersecurity Professionals:
- Layered Defenses: Implement strict input/output validation, access controls, and runtime monitoring for all LLM-integrated systems.
- Red Teaming: Regularly test LLMs with adversarial prompts and scenarios.
- Data Governance: Vet and track all training and fine-tuning data sources.
- Human Oversight: Require manual approval for high-risk or privileged LLM-driven actions.
- Stay Informed: Monitor advances in hybrid neuro-symbolic architectures and formal verification, as these may offer more robust, explainable, and secure AI in the future.
In summary: The architectural and fundamental problems of LLMs—especially as articulated by Gary Marcus—are not just academic concerns. They are the root cause of many practical, exploitable vulnerabilities in enterprise AI deployments. Addressing these issues requires both techniI-specific security controls.
It is funny it could not write “technical” specific
Thanks for reading. I will create more info and posts on this as it warrants more research. Remember to always review and double check the output from LLM AI.